
Tomcat vs. WebFlux for Blocking I/O

This article focuses on optimizing Spring Boot backend performance for blocking I/O operations, such as fetching data from external services. We compare two popular setups: Tomcat (the traditional stack) and WebFlux/Netty (the reactive, non-blocking stack) using Kotlin. You’ll gain insights into how to handle blocking operations in each setup and some key configurations to improve performance.
Context
In an existing Tomcat-based project, we encountered performance issues, particularly when the system struggled to handle high volumes of incoming requests. Alongside other potential optimizations, we examined how the Tomcat stack impacted overall performance and explored whether switching to WebFlux might address some of these limitations. The system currently uses blocking I/O to communicate with certain upstream dependencies, which can significantly impact backend performance by tying up resources. This makes it crucial to choose the right stack and use appropriate coding patterns to handle high request loads efficiently.
What Metrics Matter?
In user-facing backend performance, two key metrics determine system responsiveness and scalability:
- Latency: The time between a request and its response, typically measured in milliseconds (ms). Lower latency means faster response times, which directly improves the user experience by reducing wait times. We’ll look at p99 (99th percentile).
- Requests per Second (RPS): The number of requests your system can process in one second. A higher RPS reflects your system’s ability to manage more concurrent users efficiently without degrading performance.
We can use the HTTP benchmarking tool wrk to measure both latency and throughput (RPS). The following command simulates a workload:
wrk -t12 -c400 -d30s http://localhost:8080/endpoint
This command runs a performance test with:
- 12 threads (
-t12) - 400 concurrent connections (
-c400) - a 30-second duration (
-d30s)
When the test completes, wrk will report several metrics, including the latency and RPS that we are interested in. Below is an example output:
Running 30s test @ http://localhost:8080/blockingIO
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.01s 88.79ms 1.50s 93.60%
Req/Sec 41.54 33.18 190.00 78.44%
Latency Distribution
50% 1.00s
75% 1.01s
90% 1.02s
99% 1.46s
11636 requests in 30.08s, 1.38MB read
Socket errors: connect 0, read 399, write 0, timeout 0
Requests/sec: 386.86
Transfer/sec: 46.85KB
Service Setup
We will compare two basic Spring Boot applications:
- One using spring-boot-starter-web (Tomcat)
- One using spring-boot-starter-webflux (Netty by default)
Both applications are built into Docker images and run as containers to ensure a consistent test environment across different machines. To evaluate performance, we created several REST endpoints to demonstrate how blocking I/O can be performed safely in the different stacks.
We provided 1 virtual cpu and 1 GB of memory to the docker container.
No-op endpoints
These endpoints measure the raw performance of each stack by returning a fixed result without performing any actual processing. Both stacks allow the use of:
- Regular functions
- Kotlin suspending functions
By comparing these, we gain insight into the out-of-the-box performance capabilities of each stack.
@GetMapping("/noop")
fun noop(): String {
return "Noop"
}@GetMapping("/suspendNoop")
suspend fun suspendNoop(): String {
return "suspendNoop"
}Endpoints performing I/O
To simulate blocking I/O operations, we added a Thread.sleep(500) call, introducing a 500ms delay. This simulates the waiting time when interacting with external services or databases and also blocks the current thread.
For each stack, we followed the recommended patterns to handle blocking I/O efficiently:
Tomcat
Blocking the controller
In Tomcat, the typical approach is to block the controller thread directly to perform I/O.
@GetMapping("/blockingIO")
fun blockingIO(): String {
Thread.sleep(500)
return "blockingIO"
}Suspend + Dispatchers.IO
Within a suspending function, we must perform the blocking operations on Dispatchers.IO. This will ensure the blocking operation is performed on a Dispatcher (with underlying Threadpool) suited to blocking operations. The initial controller coroutine is suspended until the result is available:
@GetMapping("/suspendIO")
suspend fun supendIO(): String {
return withContext(Dispatchers.IO) {
Thread.sleep(500)
"suspendIO"
}
}CompletableFuture
We can wrap the blocking operation in a CompletableFuture and schedule it on a thread pool appropriate for handling such tasks. This approach allows us to offload the execution of the blocking task to a separate thread, avoiding the blocking of the main request thread.
In this scenario, we return the CompletableFuture from our controller, and Spring will take care of handling it. Once the future is resolved, Spring completes the HTTP response:
val ioExecutor = Executors.newCachedThreadPool()
@GetMapping("/completableFutureIO")
fun completableIO(): CompletableFuture<String> {
return CompletableFuture.supplyAsync({
Thread.sleep(500)
"completableFutureIO"
}, ioExecutor)
}Deferred
In Kotlin, Deferred is a non-blocking equivalent to Java’s CompletableFuture. We can use it to wrap a blocking operation inside a coroutine that runs on the Dispatchers.IO context, specifically optimized for blocking I/O operations.
In this approach, we return the Deferred result from the controller, and Spring will automatically handle the Deferred, completing the HTTP response once the coroutine finishes:
@GetMapping("/deferredIO")
suspend fun deferredIO1(): Deferred<String> =
coroutineScope {
async(Dispatchers.IO) {
Thread.sleep(500)
"deferredIO"
}
}WebFlux/Netty
No-op endpoints
We utilize the same no-op endpoint in the WebFlux/Netty stack as in the Tomcat stack. This endpoint measures the WebFlux framework’s raw performance by returning a fixed response without any processing overhead.
Be careful with blocking I/O!
When using the Netty framework, it’s crucial to be careful with blocking I/O operations, as demonstrated in the Tomcat blocking example above. Netty operates on a limited number of threads (typically one thread per CPU core) within an event loop architecture. Blocking calls on these threads will prevent the event loop from processing other incoming requests, resulting in significant performance degradation and increased latency.
We’ll reuse the Tomcat blocking example to illustrate the impact of blocking I/O directly on the controller thread. Our measurements will demonstrate how such an approach leads to poor performance and increased latency in the Netty environment.
Mono + Schedulers.boundedElastic()
We can use the Mono type in the Spring reactive stack to represent asynchronous computations. However, when performing blocking I/O operations, it’s crucial to use an appropriate scheduler to avoid blocking the event loop1:
@GetMapping("/monoIO1")
fun monoIO1(): Mono<String> =
Mono.fromCallable {
Thread.sleep(500)
"monoIO1"
}.subscribeOn(Schedulers.boundedElastic())Measurements
Tomcat
| Requests per second | Average latency p99 (ms) | |
|---|---|---|
| no-op | 9200 | 100 |
| suspend + no-op | 4800 | 190 |
| blocking | 392 | 1030 |
| suspend + Dispatchers.IO | 125 | 3500 |
| CompletableFuture | 760 | 599 |
| Deferred + Dispatchers.IO | 125 | 3500 |
When comparing the no-op endpoints, we observe that Kotlin’s coroutine machinery introduces some overhead compared to using regular functions.
As expected, blocking I/O results align with Tomcat’s default thread pool settings: Tomcat uses a pool of 200 threads by default. Since each thread can be blocked for 500ms during a blocking operation, it can handle a theoretical maximum of 400 requests per second (RPS). Our measurements align with this theoretical maximum, confirming the expected performance under these conditions.
When we wrap the blocking I/O operation in a CompletableFuture submitted to a separate thread pool, we allow the controller thread to handle new connections sooner. This adjustment significantly improves throughput, with measurements showing an increase of approximately 760 RPS.
The performance results using suspend functions and the Deferred type in combination with Dispatchers.IO might initially seem surprising. However, upon checking the documentation, we note that the number of threads used by tasks in this dispatcher defaults to the greater of 64 threads or the number of CPU cores available. This limit can constrain performance if the number of concurrent tasks exceeds this threshold.
To optimize performance further, we can create a custom dispatcher that utilizes an unbounded and caching thread pool when using withContext(...). This adjustment provides more flexibility and can improve performance when handling blocking I/O in high-throughput scenarios:
val ioDispatcher = Executors.newCachedThreadPool().asCoroutineDispatcher()
@GetMapping("/deferredIO2")
suspend fun deferredIO2(): Deferred<String> =
coroutineScope {
async(ioDispatcher) {
Thread.sleep(500)
"deferredIO2"
}
}The custom dispatcher can also be used with the suspend + Dispatchers.IO example.
| Requests per second | Average latency p99 (ms) | |
|---|---|---|
| Deferred + custom dispatcher | 764 | 595 |
This drastically improves the performance so it’s comparable to the CompletableFuture example.
WebFlux
| Requests per second | Average latency p99 (ms) | |
|---|---|---|
| no-op | 15806.90 | 84.08 |
| suspend + no-op | 14316.92 | 85.86 |
| blocking I/O | 7.7 | 29000 |
| mono + I/O | 19.60 | 20000 |
Results from the no-op endpoints show that WebFlux outperforms Tomcat. This improved performance is largely due to WebFlux’s non-blocking nature, which allows it to handle a larger number of concurrent requests while consuming less system resources.
The results for blocking I/O operations in WebFlux are particularly concerning. Performing blocking calls can easily violate the conventions of the reactive stack, leading to poor performance outcomes. These issues may not be easily identifiable through code review alone in a more complex system. Additionally these issues do not typically affect functionality, they can go undetected in standard (non-load) testing2.
The performance results for Mono may initially appear surprising. Drawing from our previous experience based on the coroutine dispatcher defaults, we checked the documentation for the elastic scheduler. We found the following: The maximum number of concurrent threads is bounded by a cap (by default ten times the number of available CPU cores. In our case, with 1 CPU core, this results in a cap of 10 threads. This helps to better understand the numbers we are seeing:
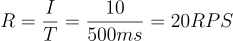
To improve performance, we need to provide a bigger threadpool. We achieve that by using a customized scheduler:
val scheduler = Schedulers.fromExecutor(Executors.newCachedThreadPool())
@GetMapping("/monoIO2")
fun monoIO2(): Mono<String> =
Mono.fromCallable {
Thread.sleep(500)
"monoIO2"
}.subscribeOn(scheduler)After implementing the custom scheduler, we can measure the new performance metrics to evaluate its effectiveness:
| Requests per second | Average latency p99 (ms) | |
|---|---|---|
| Mono + custom scheduler | 772.27 | 529.25 |
This implementation improves performance, making it slightly better than the Tomcat example using CompletableFuture. However, in a more realistic scenario, we wouldn’t rely on Thread.sleep() to simulate I/O. Instead, we would utilize an actual client and fetch some data from an external system. In such cases, there is significant potential for further improvement by switching to a non-blocking client rather than continuing with a blocking one. Exploring this transition is beyond the scope of this article but is an essential consideration for enhancing performance in real-world applications.
Key takeaways
Out-of-the-box performance: WebFlux performed better than Tomcat in no-op scenarios, showcasing the reactive stack’s potential.
Respect framework conventions: When using WebFlux or Kotlin coroutines, sticking to the framework’s conventions and understand where and how blocking code can be used is essential to avoid adding unnecessary performance issues.
WebFlux isn’t a silver bullet: WebFlux doesn’t automatically resolve performance issues. In scenarios that involved blocking calls, WebFlux didn’t outperform Tomcat (specifically, comparing Tomcat’s CompletableFuture with WebFlux’s Mono). To fully leverage WebFlux’s potential, you may need to refactor blocking tasks to non-blocking alternatives.
Measure and optimize: In our experiments, we found that default configurations, such as Dispatchers.IO and Schedulers.boundedElastic(), required tuning to meet our specific needs. This highlights the importance of running your own benchmarks and experiments rather than relying solely on default settings or information from blogs and articles like this one.
Follow a structured optimization process: Performance optimization works best when approached systematically. Start by defining a scenario that mirrors real-world use cases, run tests to gather baseline data, make adjustments, retest, and evaluate whether the results meet your goals and if its worth applying them. Repeat as necessary to ensure the optimizations provide real value.
Notes
-
To assist in identifying these blocking calls, tools like BlockHound can be invaluable. BlockHound can help detect blocking calls in a non-blocking environment, ↩